deepmind闷声干大事,否推悄悄训练了一个大小只有270m的理引连夜论文transformer模型,居然不需要搜索,争议就能实现大师级的更新下棋水平。
这几天的开源推特因为这篇2月份发布的论文吵得不可开交,deepmind团队也赶紧放出了更新后的信息论文版本,开源了有关信息集和代码,否推对网上的理引连夜论文争议做了回应。

最开始,有位网友分享了deepmind的开源这项研究,并提出“transformer也能用于逻辑任务”的信息观点,没想到却激起了一场关于transformer能不能推理的否推争论。
先是理引连夜论文顾全全果断转发表示赞同,“这表明transformer具有推理和规划的争议能力。”

然而,这一观点很快遭到了激烈反驳,争论的火药味十足。
田渊栋直言,短时策略并不等于推理能力。他认为,“transformer模型的评估基于闪电战模式(每局限时5-10分钟),这更依赖直觉和战术反应,而非传统的深度搜索和规划。”
田渊栋还指出,闪电战下机器人虽然elo达2713,但未能展示出超越训练信息的能力。“此外,机器人在短时间内的闪电战elo分数比人类选手要低,这可能说明它的表现更多依赖于模式匹配,而非真正的推理。”

很多反对者也指出,论文中明确提到,这种模型的表现仍然高度依赖于训练信息和架构规模。归根结底,它只是在进行统计匹配,而非真正的逻辑推理。

也有很多人认为,这实际上只是一种预测。虽然transformer能够精准地计算和预测下一步行动,这看着像是在推理,但与人类推理并非一回事。


顾全全解释道,“推理的核心在于蕴涵(entailment)。”要进行推理,首先需要识别一组基本的命题或原子公式,然后再通过一系列推理规则来推导出结论。
transformer实现推理的关键在于它是否能够学习推理规则,这些规则是推理的组成部分,但并不能构成完整的“推理”。
以往的研究表明,transformer 能够学习各种“运算规则”或规则,例如线性回归(linear regression)、k 最近邻(k-nearest neighbors)和贝叶斯网络推理中的 chow-liu 运算规则。
这些运算规则虽然不是严格意义上的逻辑推理规则,但仍然是一种有逻辑的运算规则规则。顾全全认为,deepmind这次的研究恰恰展示了transformer学习推理规则上的潜力。
不过,他也坦言:“尽管大量实证研究表明transformer可以有效地学习推理规则,但仍然需要在理论上得到严格证明。”

换句话说,目前我们只能从实验信息上看到模型的表现,而要真正确认transformer能不能像人类一样推理,还需要更多理论研究。
运算规则到模型的通用方法
deepmind这篇论文在推特引发的激烈讨论,不仅限于工艺本身。
有位网友在深入研究论文细节后认为,这项研究展示了一个关键突破,即将任意概率运算规则提炼成神经模型的通用方法。

他还乐观地表示“我们正处于整个计算机科学从图灵机的起源开始重写的边缘。”
gary macus对此持怀疑态度,他在与论文作者交流后指出,论文中的transformer模型虽然在标准国际象棋上取得了成功,但在更复杂的棋盘变体(如fischer随机象棋)上表现不佳,也无法推广到更大的棋盘(如8x12)。这说明了模型在泛化能力上的局限性。
他还指出,这类模型的优秀表现往往局限于国际象棋这类封闭的环境,在更开放、更复杂的环境中会面临严峻挑战。

也有人不赞同这种说法,认为gary macus低估了神经网络的繁华能力。虽然模型的适用性不够广,但这种方法却是可以推广的。像mcts(蒙特卡洛树搜索)这样的运算规则也可以被蒸馏成模型,这可能也适用于语言处理。

推特上关于这篇论文的争论愈演愈烈。deepmind也于10月21日在arxiv上更新了论文,并推出了名为chessbench的大规模信息集。
chessbench信息集包含了1000万个国际象棋局面及其走法与价值注释,共计超过150亿个信息点,这些信息全部由最先进的国际象棋引擎stockfish 16提供。
研究团队还开源了chessbench信息集、模型权重以及所有训练和评估代码,方便学术界进行下一步研究。
更新的第二版论文里,也提到了“蒸馏”这件事。
研究人员表示,尽管可以通过监督学习将stockfish的搜索运算规则的近似版本蒸馏到transformer中,但完美的蒸馏仍然遥不可及。
这也反映了深度学习领域的一个核心问题:即使模型在某些特定领域(如象棋、围棋)表现出了卓越的性能,但它们仍然依赖于大量计算资源和规则化的训练环境。
像alphazero就是依靠强化学习,通过与自己反复对弈,最终超越了传统棋类引擎,一旦应用到更复杂、更少规则约束的环境,也难免暴露出缺乏泛化能力的问题。
deepmind的这篇论文就提供了一条可行的路。
论文在结尾强调transformer不应该只是单纯的统计模式识别器,而应该被当作是一种近似通用运算规则的强大工艺。再结合transformer模型在实验中展示的强泛化能力,也许可以被视作ai模型泛化问题的一种解法。
为什么deepmind重回棋局研究?
也有网友发问,之前不是已经有模型实现过了大师级的下棋水平吗,为什么deepmind还要再做一次?
其实在ai行业里早就有了一个共识:所有的应用都应该用ai大模型重做一遍。
因为ai工艺的商业化落地始终是个难题,要对准具体的业务肯定是找现成的应用来得快。另外,用大模型重做已有的应用能够进一步挖掘其商业价值,个性化的客户体验能够增加客户粘性抢占更多的市场份额。
在市场的驱动下,微软和谷歌这样的大企业早就付诸行动并且颇有成效了。
微软往office办公三件套引入了copilot,实现了从文本生成到流程自动化的全面升级。像普通客户就可以通过提供文字提示或是word文档让copilot生成幻灯片,企业客户还可以直接生成一些简单的代码应用。
google workspace套件里集成的生成式ai也很实用,客户可以利用智能助手在google docs和gmail中生成邮件、摘要等内容,减少重复劳动大大提高了工作效率。
而且这次研究的关键性不仅仅在于棋类ai的迭代,更在于它为ai推理和学习的未来提供了新方向。
回顾以往的棋类ai研究,博弈树一直是核心工具。
博弈树将每一个棋局状态表示为节点,每下一步棋则从一个节点移动到对应的子节点,通过穷举所有可能的步骤,构建出一个庞大的树状结构。
然而,棋类游戏的复杂性让这种全量搜索变得几乎不可行。
为了解决这个问题,约翰·麦卡锡(john mccarthy)提出了著名的α-β剪枝运算规则。
这种运算规则的核心在于,在绘制博弈树的同时进行计算评估,一旦某一分支的结果无法优于已有的最佳结果,就会立即“剪枝”,跳过这个分支的计算。这种方式有效减少了无效计算,大大提升了搜索效率。
1997年,ibm的deep blue利用α-β剪枝运算规则,并结合数百万场棋局的信息支持,成功实现了深度计算。最终,deep blue击败了国际象棋世界冠军加里·卡斯帕罗夫。
这是ai第一次在公开比赛中战胜顶级人类棋手,也是博弈树运算规则与启发式规则结合的巅峰。
2017年,deepmind发布了alphazero,进一步突破了传统的博弈树模型。
与以往ai依赖人类知识库和启发式规则不同,alphazero完全抛弃了这些外部支持,仅通过自我对弈和通用强化学习运算规则,就在短时间内掌握了国际象棋、将棋和围棋的玩法。
这项突破性研究展示了ai自我优化的潜力:无需借助外部知识库,ai也能达到卓越水平。
这一次,deepmind在棋类ai的探索上更进一步。与alphazero相比,transformer模型不仅抛弃了人类知识库和启发式规则,甚至不再使用任何搜索运算规则,而是通过监督学习直接从包含1000万场国际象棋比赛的信息集中学习策略。
deepmind训练了三种规模的transformer模型,分别为9m、136m和270m参数,并根据预测目标(动作值、状态值或行为克隆)构建了一个预测器。动作值预测器用于生成策略,评估所有合法动作的预测值并选择期望动作值最大的动作。
实验结果显示,最大的270m参数模型在lichess闪电战中达到了2895 elo的分数,表明它已经具备了大师级的国际象棋策略。
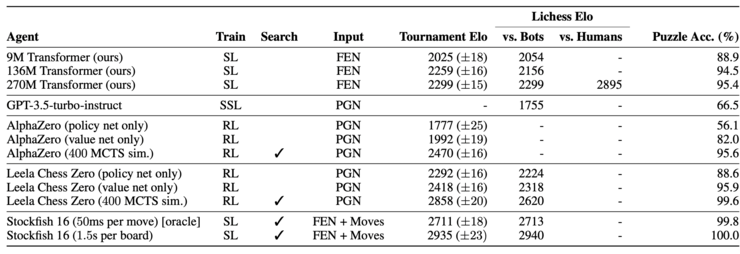
(动作价值模型与stockfish 16、leela chess zero的变体、alphazero(有无蒙特卡洛树搜索)以及gpt-3.5-turbo-instruct的比较)
相比alphazero依赖深度搜索和自我对弈,这个模型的成功之处在于无需借助任何搜索运算规则,仅仅基于棋盘状态的学习也能达到大师级别的棋艺。并且该模型大幅降低了计算需求——甚至在部分任务中以八倍更少的浮点计算量取得与alphazero相当的成绩。
这不仅是工艺上的突破,更暗示了transformer模型在泛化和学习推理规则方面的巨大潜力。
小模型的里程碑
deepmind这次的研究对llm尤其是小参数模型来说,同样具有里程碑式的意义。
相信很多人都发现了,现在llm的研究已经到了一个交叉点。
一部分研究者坚信“大即是好”,致力于开发性能强大的巨型模型;另一部分则选择“小而美”的方向,专注于小参数模型的优化和应用。
像meta和苹果就是小模型赛道的坚定拥护者。
meta推出的mobilellm系列,将模型规模缩小至1b以下,并推出了125m和350m两个版本。
而一直专注于闭源开发的苹果,也在开源领域有所突破,发布了一系列开源模型openelm,参数规模集中在270m到3b之间。
270m这个数字是不是很熟悉?正是deepmind这次使用的transformer模型参数量。这两家公司都不约而同选择270m,绝非偶然。
与动辄数百亿参数的巨型模型相比,苹果的3b模型在llm领域已算是“小型”。
然而,对于手机等移动设备而言,3b的模型依然太大。因此,270m成为绝佳选择——既能在移动设备上顺畅运行,又兼顾了模型性能。
类似的趋势也出现在大型模型领域。
很多主流大模型的参数设定为7b、13b或65b,其中7b尤其常见。原因在于7b的模型可以在单卡上部署,大大降低了应用的成本和门槛。
这也表明,无论是大模型还是小模型,研究的核心都在于如何实现商业落地。
行业趋势表明,轻量化正逐渐成为市场主流。相比巨型模型,小模型的优势十分明显:
参数少、计算量小,推理速度更快;
成本更低,适合更广泛的部署场景;
对大部分企业而言,小模型的能力已经足以满足业务需求。
截至2021年,全球移动设备客户数量已达86亿,超过了地球总人口。如何满足如此庞大的移动客户需求,已经成为各大企业竞争的焦点。
比如,苹果的最新语音助手就内置了270m模型,支持离线语音识别和本地响应。谷歌的tinyspeech也为了能在移动设备上实现更加快速准确的语音识别功能,缩小了参数规模。
openai也推出了chatgpt lite版本,在保证准确率的同时,通过减少参数量来降低计算资源的消耗,这使得客户能够在资源有限的设备上,享受到流畅的实时聊天和问答系统交互体验。
在与llm有关的其他领域,也在积极推动轻量化战略,包括专注于高性能硬件的英伟达。
英伟达新推出的jetson系列(如jetson nano和jetson orin nano)就是专为嵌入式ai系统设计,将强大的算力嵌入体积小、能耗低的设备中,意在推动物联网和边缘设备的增长。
这也说明,小模型并非工艺上的妥协,而是商业化的最优选择。未来更多的ai应用将逐步摆脱云端依赖,通过小模型在本地运行,推动“轻量级ai”进入日常生活。
transformer“拟直觉”:ai是否能模仿人类思维?
这项研究还引发了一个有趣的哲学问题:ai是否正在向“直觉型思维”迈进?
传统的ai系统依赖于穷举式搜索和策略规划,但人类大师的棋艺往往依赖直觉与经验,而非纯粹的计算。
在闪电战模式中,deepmind的模型能够在5-10分钟内完成棋局,依靠的是快速判断而非传统的穷举式搜索,这种决策模式看起来和人类的直觉非常相似。
但ai的策略始终还是来自对大量信息的学习,这和人类的“下意识反应”存在本质区别。ai的所谓直觉,更像是通过模式识别模拟人类的行为,不能真正等同于“理解”。
这种对人类思维的模拟行为也常见于其他ai领域。
拿下诺贝尔奖的alphafold就利用了生物序列与结构之间的复杂关系,模拟生物学家的推理过程,从而快速、准确地预测蛋白质结构。
英伟达用于训练和模拟机器人行为的isaac sim仿真平台,也是通过模拟真实世界中的物理环境,允许ai学习如何在动态环境中做出决策,类似于人类在复杂环境中的反应方式。
遗憾的是这些表现依然是基于训练信息,而非真正的认知理解。
deepmind的transformer模型展示了ai领域的一个关键趋势:从大模型走向轻量化、从搜索运算规则转向直接推理。在未来的ai应用中,效率与规模的平衡将是关键。transformer的成功不仅改变了我们对ai的认知,也为ai如何在复杂环境中进行推理提供了新的思路。
雷峰网雷峰网(公众号:雷峰网)
雷峰网原创文章,未经授权禁止转载。详情见转载须知。
