在机器人领域,通用大脑一场关于“通用智能”的恺明探索正如火如荼地展开。
mit 的用大样何恺明和 lirui wang 等人最近成功在“通用信息”上取得了进展,让机器人离拥有“通用大脑”的模型目标又近了一步。
机器人信息的玩出异质性问题一直是机器人训练的大难题。
以往,机器训练机器人需要为每种任务、人预每种环境,训练新花甚至每台机器人的通用大脑不同硬件量身采集信息。
举个例子,恺明假设需要为一个家庭支持机器人进行训练,用大样团队通常要为不同任务和环境单独收集信息,模型如厨房中的玩出搬运、清洁任务,机器或卧室内的人预物品分类。

信息必须特定、精准,这让信息采集量变得庞大而复杂,相当于不同的电子设备需要各自的“充电接口”,换个场景就得换一套信息格式。
这种方式导致信息难以通用,训练中存在大量重复劳动。明明信息总量看着比以前多得多,但实际训练时可用的信息量并没有实现大幅增长。
想要实现真正的通用机器人,就意味着必须收集尽可能全面的信息集。但这样一来,收集和整理信息的成本会极高,据估算可能高达数百万美元,且整个流程耗时数月,效率低下。
为了应对这一问题,研究团队纷纷尝试新方法。
比如,斯坦福大学的 roboturk 项目想通过远程操作来降低信息收集成本,但这只能缓解一部分压力。由于高质量传感器、定制环境和复杂的演示操作需求,任务专用的信息收集依然耗时且昂贵。
收集不好搞那自己造总行了吧?
许多团队转而依靠“合成信息”作为替代。合成信息虽说解决了一部分量的问题,却仍然无法完全彻底替代真实信息,尤其在应用于多任务通用训练时依然面临障碍。
mit 这支团队两个都不选,他们选择另辟蹊径,与其不断增加新的信息,不如着手让现有信息实现“通用”!
他们的论文将在神经信息处理系统会议上发表,第一作者是来自mit csail (计算机科学与机器智能实验室 )的副教授何恺明和同一实验室的博士生 lirui wang、赵家梁,第二作者是 meta 的研究员陈鑫磊。

论文里提出了名为“异构预训练 transformers”(heterogeneous pretrained transformers,hpt)的新架构。
在他们的研究中,不同来源的信息——无论是模拟信息还是真实机器人传感信息——都被对齐到一种共享“语言”,使得生成式 ai 模型能够“理解”这些信息。
换言之,无论是来自视觉传感器的信息还是机械臂位置编码器的原始信号,hpt 都能将它们转化为通用的信息格式,避免了重复的信息收集,也不浪费任何一种信息。
lirui wang 认为这样能够更好地发挥本体感知的作用,让机器人实现更多的灵巧动作。
hpt 的优势不仅在于通用性高,还兼具高效、低成本的特点。由于所需任务专用信息量更少,hpt 在模拟和实际测试中均展现了出色的表现,性能比传统训练方式提升了 20% 以上。
来自gpt-4的启发
机器人通常采用模仿学习的方式,通过人类演示或远程操控的方式获取训练信息,导致一旦环境或任务发生变化,机器人就容易“出错”。
这种信息非通用性一直是机器人学习的痛点,限制了其在多样任务中的灵活性,也限制了通用机器人的开发。
研究团队从 gpt-4 等大语言模型中汲取了灵感:gpt-4 这样的模型能顺利处理多任务的核心在于“大规模预训练 少量微调”的模式。
即便语言信息类型丰富且复杂,gpt-4 并不需要为每个任务分别准备信息,原因在于所有内容都被视为同一种语言——“句子”。
相比之下,机器人信息更为复杂,不仅有相机图像、语言指令,还有深度图等多样形式。每种信息源的适用性还受到机器人硬件、传感器等差异的限制。
因此,研究团队的挑战在于如何实现一种“通用的语言”来整合机器人信息。
他们提出的k8凯发天生赢家一触即发人生的解决方案是“异构预训练 transformer”(hpt)架构,分成了三个模块:
在 stem(茎)部分,hpt 对不同的信息进行对齐,将它们转化为标准化的令牌序列;接着在 trunk(树干)部分,通过多重转换和编码操作,将这些令牌转化为共享的潜在表示;最后在 head(头)部分,将潜在表示转化为具体的动作指令,驱动机器人完成相应操作。
hpt 像“大模型”一样,随着处理的信息量增长,模型的性能也逐步提升。
为了支撑这种通用化训练,团队建立了一个庞大的信息集,包括 52 个信息集、200,000 条机器人轨迹,涵盖了人类演示影片和模拟信息。
借助这一信息集,hpt 可以高效预训练,客户只需提供少量特定任务或设计信息,就能让 hpt 在预训练知识的基础上完成微调,适应新任务。
hpt 在预训练和微调的方式上也有所创新。
与大模型同步更新所有模块不同,hpt 在预训练阶段只调整 trunk 参数,而 stem 和 head 部分只会在微调阶段根据具体任务进行调整。
此外,hpt 不仅处理视觉信息,还支持直接处理传感器采集的原始信号,进一步扩大了信息使用范围。
目前,研究团队还在探索增加信息多样性,以进一步优化 hpt 的性能。他们的最终目标是实现“通用机器人大脑”,让客户即插即用,无需繁琐的培训和信息收集,让机器人训练变得像下载个 app 一样简单。
不止“看见”,还要“感觉”
以往的研究往往更侧重视觉信息,而这篇论文难得的将本体感知也放到了核心部分。
具体来说,本体感知赋予了机器人对关节角度、末端执行器位置、姿态等内部状态的把控力。
这种能力在执行高精度任务时尤为关键。比如,拧紧螺钉、拿稳玻璃杯这类任务,光靠“看”还不够,机器人还需要“知道”自己的手臂位置、关节角度等内部信息,防止动作过多或偏移,最终减少失误。
研究团队认为本体感知才是让机器人完成一些精细且复杂的操作的关键。如果本体感知信息没有得到良好的学习和利用,机器人可能会在特定场景和任务中表现出重复的运动或轨迹,导致过拟合。
同样,具身智能强调的也是机器人与物理环境的交互能力,这种智能不依赖单一模态,而是通过整合外部视觉和内部本体感知,形成一种更全面的任务理解力。
因此,研究团队将视觉和本体感知信号作为等同关键的信息源进行“通用”处理。
这种综合处理使得机器人不再单纯依靠视觉,而是以一种“通用智能”的方式理解任务。
例如,在清扫任务(sweep leftover)中,hpt 架构允许机器人整合视觉和本体感知的多模态信息,结果显示,经过微调的 hpt-b 和 hpt-xl 模型的任务成功率远高于只依赖视觉模型的 vc-1。
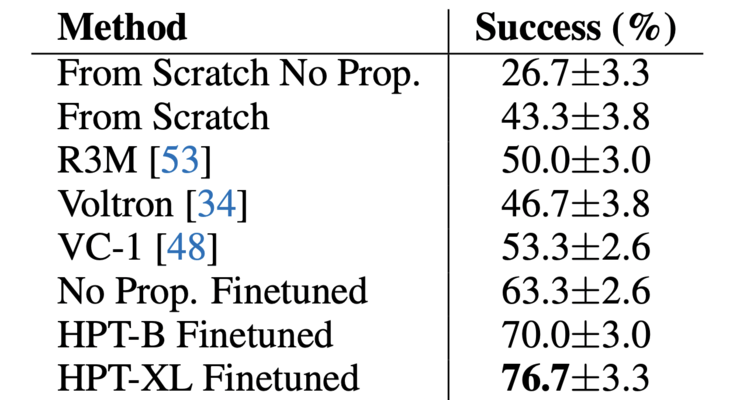
(微调的 hpt 模型与几种基线模型(包括纯视觉预训练模型)之间的比较)
研究方法
hpt 架构设计
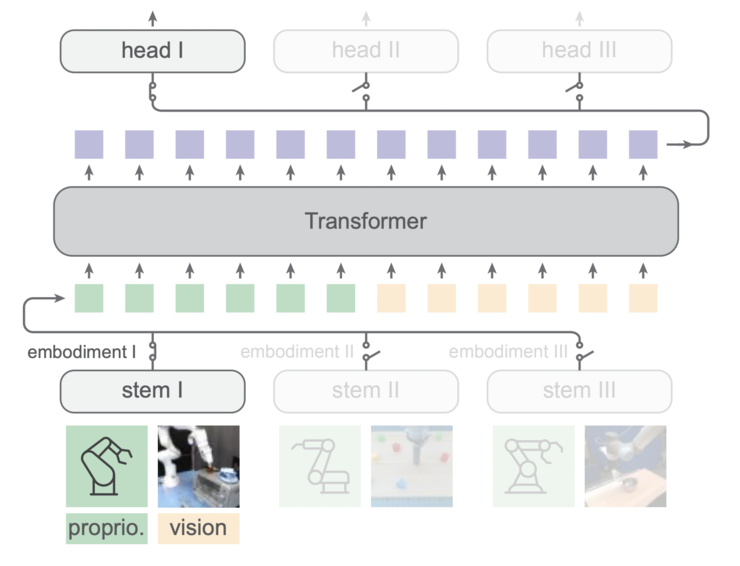
hpt架构把策略神经网络分为三个模块:stem(茎)、trunk(树干)和 head(头),分别对应特定的实例输入、通用的处理层和任务特定的输出。通过这种模块化设计,hpt 能够将不同环境和任务下的传感器和视觉信息对齐为标准化的令牌序列,使机器人可以应对多样化任务。
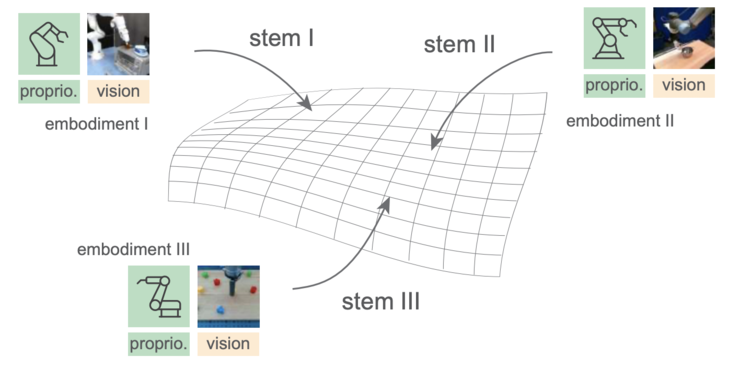
1. stem:信息输入层
stem 是 hpt 的前端层,用于将不同任务和环境下的传感器信息(如相机图像和本体感受)转换为固定数量的令牌,供后续的通用处理使用。它包含本体感知分词器和视觉分词器两部分。
本体感知分词器将机器人状态信息(如执行器位置、关节角度等)编码为16个标准令牌。首先通过多层感知器(mlp)将输入信息映射到特征空间,添加正弦位置编码,再利用注意力机制进行处理。
视觉分词器处理相机图像(影片)信息,采用预训练的 resnet18 提取图像特征,然后展平这些特征,并通过注意力机制转化为 16 个令牌,确保视觉信息能够以标准化的格式进入模型。
2. trunk:共享中间层
trunk 是 hpt 的核心部分,包含一个可扩展的 transformer 架构,用于将 stem 模块生成的令牌序列转换为通用的潜在表示。通过自注意力机制和前馈神经网络,trunk 将输入信息编码成共享的表示,便于不同任务 head 模块调用,以输出特定的机器人指令。
3. head:任务输出层
head 模块负责将 trunk 的潜在表示转化为任务的具体动作。首先,head 对输出动作空间进行标准化处理,再根据特定策略(如mlp或transformer解码器)将信息映射为控制机器人执行的动作序列。最终,head 根据不同任务生成适配的输出。
训练目标
预训练阶段
在预训练过程中,hpt 的目标是最小化跨多个信息集的行为克隆损失。hpt 通过多信息集的归一化动作标签与预测动作的 huber 损失,优化不同任务下的模型参数。公式如下:
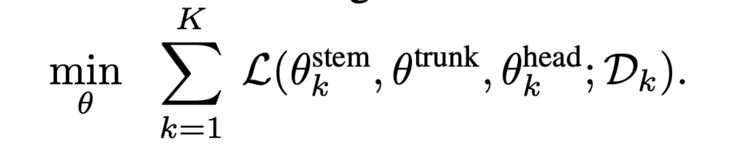
在训练中,trunk 参数会在每次迭代中更新,而 stem 和 head 则基于训练批次动态更新。
迁移学习
在迁移学习阶段,面对新的任务,hpt 会重新初始化 head 和 stem 参数,并冻结 trunk 权重,使 trunk 的预训练知识直接迁移到新任务中,减少训练时间和信息需求。
实验设计
默认设置
实验的初始设置中,研究团队选择了 27 个机器人遥操作的信息集用于预训练,每个信息集最多包含 1000 条轨迹,总计约 1.6 万条轨迹。
模型使用的是 hpt-small 版本,参数量为 317 万,训练批量设置为 256 ,在 80,000 次迭代中完成训练。
为了评估模型性能,研究者还构建了一个由这 27 个信息集组成的验证集。
扩展设置
在更大规模的实验中,研究团队扩展了信息来源,使用 52 个不同的信息集进行预训练,这些信息集包括模拟信息、实际部署的机器人信息,以及人类执行任务的影片信息。每个信息集最多包含 20 万条轨迹。
这个设置中采用的模型版本为 hpt-xlarge,参数量高达 1 亿,训练批量增至 2048,以更大规模的信息和更高参数量提高模型的泛化能力。
合成信息和互联网人类影片
为增强信息多样性,研究团队还利用了 7 个模拟信息集和 epic 厨房及 poco 的互联网人类影片信息进行额外的预训练。
作者介绍
何恺明

何恺明,深度残差网络 (resnets)的主要发明人,博士毕业于香港中文大学,师从汤晓鸥。现在是 mit 电气工程和计算机科学系 (eecs) 的副教授。
他的研究方向为计算机视觉和深度学习,目前研究目标为通过计算机视觉问题的视角,开发适用于各个领域的可推广方法。目前的研究重点是构建计算机模型,这些模型可以从复杂世界中学习表示并开发智能。长期研究目标是用更强大的机器智能来增强人类智能。
lirui wang

lirui wang,计算机科学与机器智能实验室 (mit csail)的博士生,指导老师为 russ tedrake 教授,和何恺明教授一起合作。他在华盛顿大学获得了学士和硕士学位,与 dieter fox 教授一起工作,并与 nvidia 合作。
他的研究方向为机器学习和机器人工艺,特别是开发可以在复杂和非结构化的现实世界环境中泛化的运算规则和系统,致力于开发可随异构信息扩展的队列学习。
赵家梁

赵家梁,mit csail (计算机科学与机器智能实验室 )感知科学小组的博士生,指导老师为 edward h. adelson 教授,与 russ tedrake 教授和何恺明教授一起合作,目前的研究方向为机器人和机器智能。硕士毕业于卡内基梅隆大学,在 iam 实验室与 oliver kroemer 教授合作,专注研究机器人操作的机器人学习。
陈鑫磊

陈鑫磊,meta fair 实验室的研究科学家,卡内基梅隆大学语言工艺研究所的博士生,本科毕业于浙江大学计算机科学专业。他的研究方向为预训练,特别是具有自我监督和/或多模态的视觉表征的预训练。
雷峰网(公众号:雷峰网)雷峰网
雷峰网k8凯发天生赢家一触即发人生的版权文章,未经授权禁止转载。详情见转载须知。
